Vector embeddings are values that you store in a database so you can do searches/matches for things that are related (sugar is more related to honey than it is to pen). Embeddings are these big combinations of numbers that somehow embed the meaning of words. Companies with good search functionality on their websites use this. For example, “azure-happy holiday-shirt” should match “blue festive Christmas shirt”. My own AI efforts are focused on matching candidates to jobs — same principle.
When I first started working with vector embeddings, I was creating embeddings on skills and roles together, along with some short descriptions of the evaluation. But I wasn’t looking at whether my matches were doing what I wanted them to do. Great, I have a match, but was it a good match? I had to answer that to know if I was doing right by job candidates. To me, laying out results in a table makes sense.
Tables are natural. You can see if you’re doing things right by looking at the data on a grid.
Here’s the random skill combination that a random job description may have:

Boy, do they ask for a lot. Maybe it’s not that unusual.
Here’s how some imaginary candidates match based on the skills that I gave them. I’m using embeddings to do all this, keep this in mind. I’ll restrict myself to Critical and Required requirements. I also have Preferred and Optional. I add remarks on what makes these useful.
Does the resume say that the candidate has the skill?
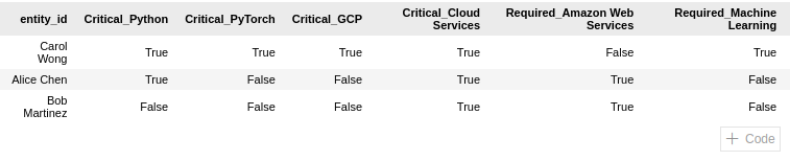
True or False, that’s all I ever want to know when I’m performing my searches.
Category Summaries

The category summaries give me the quick high level overview. Add some color and I can have an even stronger impression of where my requirements are being met.
What skill from the candidate’s resume best matches what I’m looking for?

We also need to see what we allowed to match. The values in the rows are the vectorized resume skills with the best match to the vectorized job description skills. I gave Bob ‘Python Scripting’ but this didn’t make the cut…
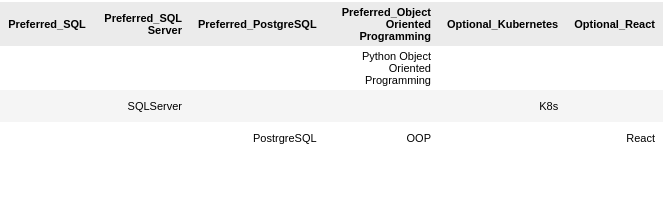
Gosh, a bunch of people with SQL Server and PostgreSQL but no SQL. Too bad. At least someone with K8s in their resume got credit for Kubernetes.
The learning here is that I need to supplement the very detailed JSON evaluation that I build from the resume with alternatives, abbreviations, aliases.
A table with scores, so we can rank candidates based on overall match quality. Each Critical skill rates a 20, Required is a 10, etc
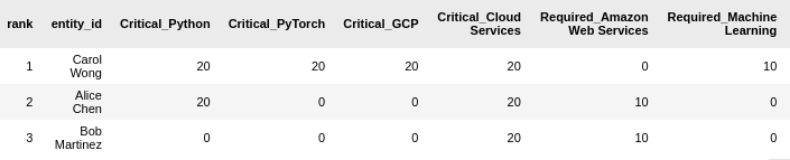
And the rest with candidate totals at the end

Carol’s resume tells us that she has more of what we need. Is she better at Python than Bob? Can she setup an org on Google Cloud? Who knows. But she has the best matches by far. On a skills based hiring strategy, she’s our front runner.
And the cosine distances. 0 is right on the nose.

With the not great matches, I know that I’ll have to do feature engineering and plug in variant and generic names for skills. After adding those, my vector matching should do much better and help with giving candidates credit for what’s on the resume.
I use other ratings and evaluations as well for my candidate evaluations so all I need to do is tie these together with the skill match scoring above. With that done, I can filter my candidate dataset on conditions that are best suited for each hiring strategy. Each hiring strategy emphasizes different candidate experiences and attributes. More on that soon.
Tools used: Python, LlamaIndex, Chroma (local vector database), OpenAI embeddings, Jupyter notebooks, pandas