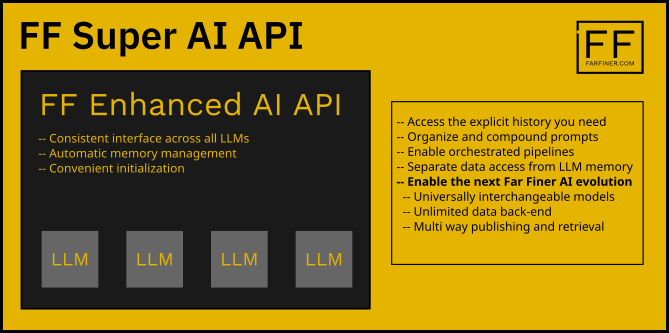
With LLM access through APIs, LLM memory is not unlimited and it can get expensive. And even when when it becomes no longer limited and hopefully cheaper in 2025, we will still have the problem of being clear in how we want an AI to answer our requests. Paid chatbot users have it good; the true cost of those long interactions are hidden from you, but somewhere gallons of water are being gassed out and cash is just burning up.

While developing my Adaptive Rule Based Evaluation System, I’ve also been enhancing the Far Finer AI APIs to make my AI interactions more flexible, cheaper, faster, more powerful, but development costs money.
Enter Microsoft, they have money.
A few days ago, I received $1000 from Microsoft from their Microsoft For Startup Founders program. At the same time, I ran out of Anthropic (Claude) credits and so I needed to exchange Claude for the Azure OpenAI API, which is different from the regular OpenAI API. The Far Finer API design allowed me to build a new class for Azure. Unfortunately, GPT 4o does not return the same level of detail as Claude. There’s fewer skills returned when evaluating resumes, for example. This meant that I again needed enhance the APIs to overcome shortcomings. Some work later, I can now ask questions that use pre-defined inputs and named prompts. The history is the named prompt interactions that I want the LLM to use.
ffai.clear_conversation() # this clears the llm memory
response = ffai.generate_response("What did you say to the math problem?",
prompt_name='final query',
history=["pet", "math", "greeting"])That last command builds this prompt that’s sent to the LLM. Notice the history part with labeled prompt tags, much like HTML.
<conversation_history>
<interaction prompt_name='pet'>
USER: concatenate these words: cat, dog
SYSTEM: catdog
</interaction>
<interaction prompt_name='math'>
USER: what is 2 +2?
SYSTEM: 2 + 2 equals 4.
</interaction>
<interaction prompt_name='greeting'>
USER: how are you?
SYSTEM: I'm functioning optimally and ready to assist you with any questions or tasks you have. How can I help you today?
</interaction>
</conversation_history>Based on the conversation history above, please answer: What did you say to the math problem?
THE ANSWER: I said, “2 + 2 equals 4.”
And then later on, I can ask another question, which simply asks the LLM how it answered “the question”
response = ffai.generate_response("What did you say to the question?",
prompt_name='really final query',
history=["final query"])
print(response)THE ANSWER: I said, “2 + 2 equals 4.”
This allows me to build very efficient interactions from my managed rules.
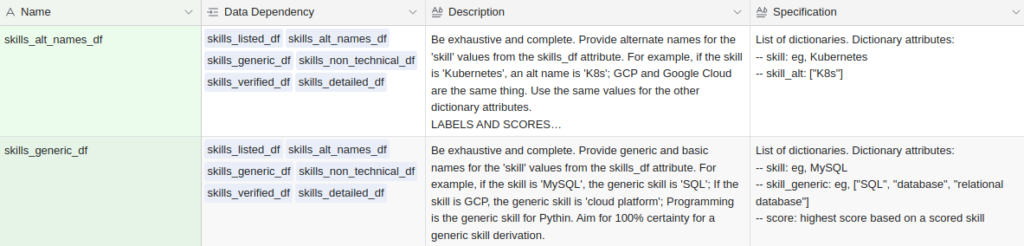
Each one of those items in the Data Dependency is an attribute of a doc (resume) evaluation. The attribute name happens to also be the named prompt. If I don’t name a prompt, the question/ask becomes the name for itself.
Better, but never done. In the future, I may decide to embed a full recursive history that tells me how each individual interaction was used, but I don’t need that now.
The Benefits
- Cost — I get access to any and all previous interactions, even if I devoid the LLM of the chat history that, for example, chatbots rely on. I can store away interactions and then re-use them as needed.
- Speed/Efficiency — Less information sent to the LLM means faster responses.
- Explicit guidance — Feed the LLM the exact information you want it to use.
- Easy RAG — This is a form of RAG, which happens to use data that only lives for the life of the AI client. And because it’s independent history from the main LLM’s history, I can reuse that data store with other LLMs; for example, I can make history available across any AI model from any vendor. Maybe I pass a * and I make all history available. And maybe I backend a different data store to the dictionary, let’s say a whole database via something as cool as DuckDB+pandas. And I enable some embedding type matching which makes a question only ever look at the data in a database that seems the most relevant. I can create embeddings on anything and everything in a database.
Beyond
- Beyond RAG — RAG is one way, but imagine a dictionary that automatically publishes to a database, which can extend to reporting, monitoring, and observability.
- AI investment — Building blocks for further prompt engineering, and more advanced solutions.
What’s possible just keeps on expanding.
For more information: https://github.com/antquinonez/Far-Finer-AI-Clients